其实很久很久之前就想去写这篇博客了,因为疫情学习工作等等等等各种原因一直拖着。直到最近在上海隔离,发现时间一下变多了起来,于是决定把TODO List上的这个事项给解决掉。这篇博客主要是想总结一下Jupyter给数据科学领域在不同场景下的应用以及商业模式的探索,同时结合一下自己的思考以及灵感。
首先简单说说 Jupyter 这个项目把,从最早的Ipython开始,到后面的 Jupyter Notebook,再到现在基本做数据的人都会用的 Jupyter Lab 来讲,它极大的改变了我们在数据科学行业的探索上的工作方式。从学生个人开发者到Top tier 的tech firm 我们都能看到 Project Jupyter 的影子。经过我自己的观察和总结,现在Project Jupyter 被广泛使用的大致有下面2类按照使用对象分类的场景。
提供技术为他人服务
第一类就是最常见的通过提供技术为他人服务的组织,具体有以下几种代表
云服务商
云服务商,不用多说大家都知道是什么。这里大部分人有个误区就是数据科学不全都是做机器学习/深度学习,很多厂商往往会用机器学习/深度学习来做噱头,但是其实他们提供的产品用来做数据科学也完全是可行的。云厂商们的优势很明显,有大量的机器集群,技术专家以及业务经验。劣势就是不够接地气,在落地应用到具体业务的时候还是需要使用者们去阅读文档来更好的使用。当然作为使用者,如果度过了这些工具的learning curve,那还是很舒服的。
AWS Sagemaker
AWS Sagemaker 还是比较出名的,业界大部分机器学习的工程都跑在这个上面。他们自己也是 Projec Jupyter 非常重要的贡献者之一。他们对Project Jupyter 在工具层面上的改动并不是特别大,但是在算法框架上和使用案例上给了非常好的支持。Sagemaker 的 Python SDK也在 Github 上开源了。可以看到通过使用他们的SDK,用户可以很直接的把自己的算法放上去跑来降低迁移成本。除了降低算法框架上手难度外,他们还整合了自己的其他产品的矩阵比如S3存储服务,可以直接从bucket里面指定数据。这点我觉得还是挺不错的。
Google Colab
Google 的 Colab 其实更多是对 Notebook 这个项目进行了整合,然后配合他们自己研发的TPU和业界著名的Tensorflow。个人使用了一段时间之后总体感觉还是卖资源为主,并没有和自己的其他产品形成特别明显的矩阵。当然有可能确实是项目组不差钱。不过和社区倒是做的非常不错,直接从Github导入,当然白嫖还是爽的。此外对于 widgets 的优化做的还挺有意思,可以直接从里面构建出一个小APP出来。总体感觉还是比较技术导向,和业务距离的比较远。
Aliyun PAI DSW
PAI的 DSW 最近推出了V2。还没仔细测评,但是大致就是一个CPU/GPU实例上放了Jupyter Lab + VS Code Online。然后有一些自己的magic method和特殊render的cell。主要优势可能还是和自己的产品生态绑定在一起了,方便从 MaxCompute 去读取数据,推送计算任务,甚至定时运行等等。而且还可以新建数据集和管理数据集。具体细节还没有看,但是缺失案例且文档不太好读。
Azure
Azure对于 Jupyter 的 adoption 还在 Notebook 的阶段。感觉没有特别的Differentiate自己的产品,也可能是个人对Azure认知不足导致的,有待后续完善。
行业垂直机构/组织
这类组织往往借助 Jupyter 来更好的推出他们的其他的服务。这类组织和云技术厂商相比,他们更贴近业务,在行业上更加垂直。同样由于自己的算法框架导致有一定的learning curve,但是由于场景更聚焦,所以curve也相对平缓一点。
Paper Space
Paper Space 是一家专注提供给学校和科研机构低价GPU的SAAS公司,用户可以一键创建他们自己的Notebook镜像并训练自己的模型。优势主要还是在价格上。
Quantopian
Quantopian 是一家做金融量化交易的公司,有自己的量化数据集和交易代码框架,让用户去上面写策略为主。他们也是停留在了Jupyter Notebook上面,没有更新到 Jupyter Lab。但是我认为这是能理解的,因为对于这家公司来说,他们的核心竞争力在于金融数据以及股票交易策略平台,而不是去做一个高效的生产工具。
提供技术为自己服务
第二类就是有内部业务需求的技术导向的组织,这种组织更多的是商业性公司,他们具有相对完善的数据科学专家和一定的数据积累以及技术架构。
商业公司
Netflix, 关键词: 数据探索/调度/分享/支持业务分析
Netflix对于 Jupyter Project的 Adoption真的是非常的令人叹为观止。他们在自己的博客上非常详细讲述了他们通过使用 Jupyter 在数据科学上的最佳实践,可以找个时候好好详细拜读一下。 Netflix 的Engineering 团队一直给我一种非常好的感觉,开放乐观且实用。他们在这方面配合自己的架构开发了几个特别实用的开源软件。顺便附上他们的工作流架构图: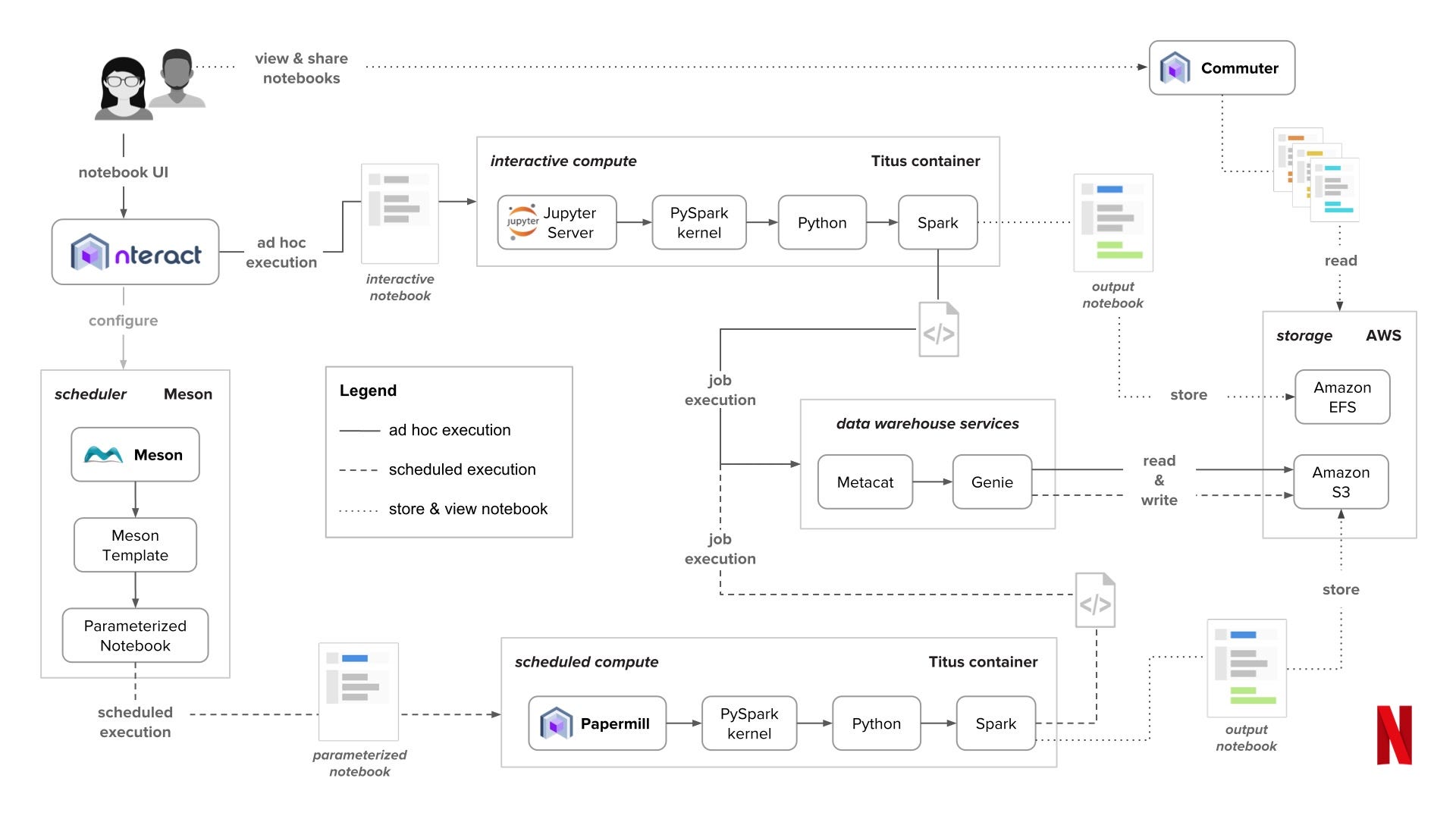
这里 Netflix 主要做了下面几个定制:
Nteract
nteract 这个项目可以说是把 Jupyter 的前端都给重写了一遍,界面和易用性都有不少的提高。比如配合他们自己开发的Data Explorer, 数据可视化真了方便了很多。
Papermill
Papermill是一个用于参数化Notebook的项目,当我们想要去测试不同参数的时候就可以使用。使用起来很简单,也很高效。非常pythonic。
还有一些就更偏向团队了,比如用于分享的Commuter,调度系统Meson/Genie 和管理AWS集群的Titus 更偏向云计算资源管理和分享,这里就不详细讲了。
PayPal, 关键词: Magic Method/配合内部架构
Paypal 在 Jupyter Con 2018 上演示了他们对于Jupyter生态的拥抱以及改动。主要还是Magic Method配合他们的大数据平台使用。个人感觉特别方便好用的是通过magic command来实现对hive集群数据的读取和导入。同时还支持Schedule以及结果的notification。源码和相关文档可以在这里找到。
Two Sigma,关键词: 数据探索/数据集成/分享/调度/配合内部架构/JVM Kernel
Two Sigma 可谓是 Project Jupyter 的主力军。现在大家能够看到的多个 Jupyter 的 feature 其实都是 Two Sigma 的team推的。他们自己的分支叫做 BeakerX,也是在 Jupyter Lab的基础之上去做了很大的改动。对于一家 FinTech 公司来说,数据可视化非常重要。如何帮助分析师们高效的探索数据之间的关系很大程度影响了公司的盈利能力。这点从Bloomberg的Terminal每年的营收就可见一斑。
Bloomberg, 关键词: 模型可视化
Bloomberg 的团队是 Project Jupyter的另一支主力军。他们在模型可视化上配合 Widget 以及 D3.js 可谓玩的是出神入化,秀到飞起。这个是他们18年在Jupyter Con的模型可视化视频,看了一次之后不禁感叹R&D有钱做出来的产品也牛逼。代码也已经开源在Github上了。
美团民宿, 关键词: IDC/Widget定制
美团技术分享原文在这。作为国内数一数二数据驱动的互联网公司,美团在数据科学方面的实战非常有启发意义,也很接地气。架构上来看和Netflix的差不多,做的事情也很类似。但是在 Widget 上做了与自己行业所绑定的内部工具,有效的提高了开发的效率,我觉得还挺不错的,也是他们能够做到Differentiate的地方。
学校以及研究机构
暂止没有什么特别好的发现,我了解的大部分学校都是以使用为主,配合Github Education Package。倒是有一些不错的插件比如 Exercise。用得好基本能替代大部分只检查答案的OJ系统了。
感想
可以看到几个非常常见的方向
- Notebook调度以及参数传入
- Notebook的分享
- 数据可视化的易用性
- 用Magic Command来配合已有的框架
- 用IpythonWidget去定制行业专属的组件或者是Extension
- 配合K8S去实现资源调度
说明大家面临的问题往往也是大同小异,但是具体如何去采纳已有方案来帮助落地实施,就取决于具体执行人/公司的情况了。我认为 Project Jupyter 在未来一定会作为交互式编程的代表作帮助人们更好的用数据去探索并改造这个世界。用中文讲叫做 未来可期。