Yuze Ma (鱼哲)
Product person who codes (or at least vibe codes). Currently shipping GPU compute at NVIDIA, previously built Lepton AI from scratch, and before that wrangled AI-HPC clusters at Alibaba Cloud. I care more about shipping than talking about shipping — if I can't prototype it, I probably shouldn't spec it. Jupyter contributor. Fueled by cooking, jazz, dubious cocktail experiments, and way too many hours in Hearthstone Battlegrounds.
Experiences
-
 Senior Product Manager NVIDIA · Apr 2025 – Present DGX Cloud Lepton — connecting developers to a global network of GPU compute.
Senior Product Manager NVIDIA · Apr 2025 – Present DGX Cloud Lepton — connecting developers to a global network of GPU compute. -
 Founding Product Manager Lepton AI (acquired by NVIDIA) · May 2023 – Apr 2025 Built the Gen-AI platform from 0 to 1 — model training, optimization, and multi-cloud deployment orchestration. Designed and executed GTM strategy.
Founding Product Manager Lepton AI (acquired by NVIDIA) · May 2023 – Apr 2025 Built the Gen-AI platform from 0 to 1 — model training, optimization, and multi-cloud deployment orchestration. Designed and executed GTM strategy. -
 Senior Product Manager Alibaba Cloud · Apr 2019 – May 2023 Led AI-HPC (Lingjun) and PAI ML platform products — infrastructure design, scheduling optimization, and commercialization. Managed 95%+ of department revenue, driving 500%+ YOY growth.
Senior Product Manager Alibaba Cloud · Apr 2019 – May 2023 Led AI-HPC (Lingjun) and PAI ML platform products — infrastructure design, scheduling optimization, and commercialization. Managed 95%+ of department revenue, driving 500%+ YOY growth. -
 Data Scientist Codemao · May 2017 – Apr 2019 Grew the data science team from 3 to 9. Built the data science workflow, recommendation system, and online judge system, expanding the business from ToC to ToB.
Data Scientist Codemao · May 2017 – Apr 2019 Grew the data science team from 3 to 9. Built the data science workflow, recommendation system, and online judge system, expanding the business from ToC to ToB.
Education
-
 B.S. Information Technology & Web Science Rensselaer Polytechnic Institute · 2016 – 2020
B.S. Information Technology & Web Science Rensselaer Polytechnic Institute · 2016 – 2020
Projects
-
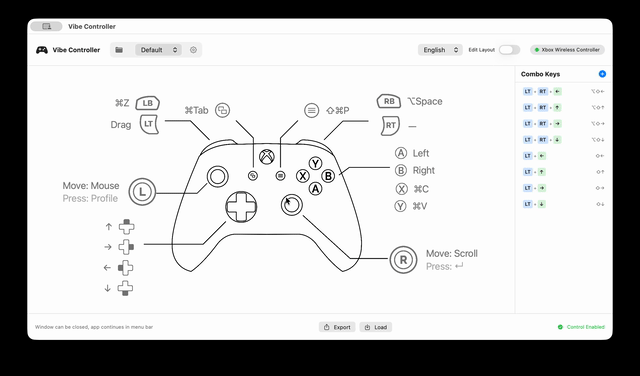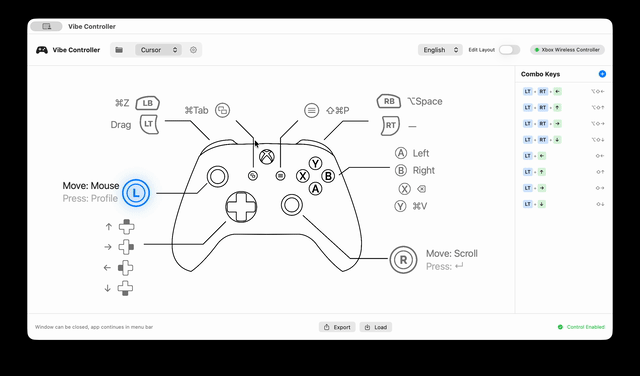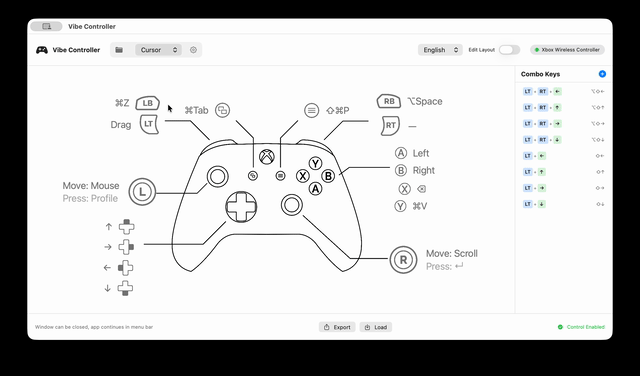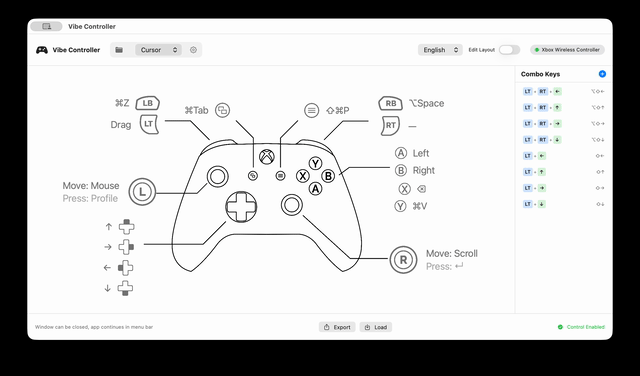
Vibe Controller
A system-level macOS tool for controlling your Mac with an Xbox controller. Menu bar app with visual button mapping, auto profile switching, app exposé mode, and fully customizable mappings. Built with Swift + SwiftUI & IOKit HID.